


Data collection
To construct a scientific fitness knowledge graph database, this study, under the guidance of domain experts, categorizes fitness content into seven key domains: exercise methods and techniques, weight loss, strength and endurance, sports medicine, biochemistry, exercise physiology, and sports nutrition. This classification aims to systematically organize and analyze fitness knowledge from both scientific and practical perspectives.The exercise methods and techniques domain includes various forms of exercise, such as aerobic workouts, strength training, and flexibility exercises, aimed at optimizing physical performance21. The weight loss domain focuses on strategies for body weight management and body composition optimization22. Strength and endurance research emphasizes techniques for enhancing muscle strength and physical endurance to improve athletic performance23. Sports medicine examines the relationship between exercise and health, with particular attention to the prevention and rehabilitation of sports injuries24. Biochemistry investigates the metabolic pathways and chemical reactions involved in exercise, elucidating how physical activity impacts internal physiological processes25. Exercise physiology analyzes adaptive changes in body systems, such as the cardiovascular and nervous systems, in response to exercise26. Finally, sports nutrition explores the role of proper diet and nutrition in supporting exercise performance and overall health, providing evidence-based guidance for personalized nutrition plans27.
To ensure the comprehensiveness and scientific rigor of the data, we selected several authoritative data sources, including China National Knowledge Infrastructure (CNKI)(https://www.cnki.net/), Wanfang Data (https://www.wanfangdata.com.cn/), Baidu Baike (https://baike.baidu.com/), Baidu News (https://news.baidu.com/), Wikipedia (https://www.wikipedia.org/), and the official website of the General Administration of Sport of China (http://www.sport.gov.cn/). These sources cover a wide range of content, including academic research, professional literature, online encyclopedias, fitness news, and policies, providing rich raw data for constructing the knowledge graph. In the data collection process, we designed search queries using the seven core areas as keywords. In both CNKI and Wanfang Data, we utilized wildcard characters (*) and quotation marks (“”) to match various forms of keywords, thereby expanding the search scope and ensuring the inclusion of relevant variants.For example, the term “sports medicine” may match related topics such as “sports medicine research” and “sports medicine therapy.” Additionally, we employed logical operators (AND, OR, NOT) to combine keywords, further improving the accuracy and relevance of the search results, such as “exercise physiology” AND “sports injuries.” Baidu Baike and Wikipedia offer fuzzy matching functions that allowed us to retrieve more relevant entries. Baidu Baike returns entries related to the seven core areas and their variants through fuzzy matching, while Wikipedia further enhances the comprehensiveness of the dataset with its broad coverage of topics. Furthermore, Baidu News pushes relevant news articles, reports, and discussions based on input keywords, further enriching the data sources. Finally, the official website of the General Administration of Sport of China provides a wealth of publicly available sports data and policy documents, covering topics such as sports training, fitness facilities, and fitness guidance, which offer valuable foundational material for the dataset. Ultimately, we collected millions of characters of raw data based on the classification of the seven core domains. However, the data collection process is still in its preliminary stage and has not yet undergone the necessary filtering and processing. In the subsequent work, we will carry out data preprocessing, including data cleaning and noise reduction, to enhance the accuracy and relevance of the data.
Data preprocessing
Although a large volume of raw text data has been collected, not all of it holds analytical value. Furthermore, text from different sources often contains various issues. For instance, data descriptions are typically presented as long, unstructured text segments, which may include special symbols, noise, or irrelevant information (as shown in Fig. 2), and there are often inconsistencies in format and structure. Therefore, prior to further analysis, we first integrate all the data and convert it into a processable format (e.g., TXT text files). We then manually filter the data to remove irrelevant or low-quality content. Subsequently, a series of preprocessing operations are performed on the filtered text to improve data quality and ensure the accuracy of subsequent analysis.

Example of Raw Data with Noise.
In the process of cleaning and preprocessing fitness data, the first step is denoising, which aims to remove irrelevant information and noise to improve data accuracy and quality28. This is achieved by using regular expressions to eliminate special characters, HTML tags, advertisements, and other irrelevant elements29,30. Additionally, stopword removal further simplifies the text by eliminating common but insignificant words (e.g., meaningless terms such as “的”, “是”, “在”, etc., in Chinese texts.)31. After denoising and stopword removal, the data enters the standardization phase, where it is uniformly encoded in UTF-8 format to ensure consistency and avoid encoding errors. Subsequently, the text structure is adjusted and divided into smaller units to facilitate more accurate capture of key information during subsequent analysis, thus preventing information overload.
Finally, we obtained 11,544 processed original samples. These samples provide solid support for the next step of entity and relationship extraction and lay a foundation for the subsequent construction of the knowledge graph.
Entity classification and relationship mapping
Based on the collection and organization of scientific fitness data, we further define and classify the preprocessed data into detailed entity types and relationship types. Considering the characteristics and needs of the fitness field, we have defined 8 entity types and 11 relationship types. This classification covers various entities and relationships in the fitness domain, ensuring a comprehensive and accurate description of fitness knowledge.
In terms of entity types, our selection is based on the core elements of the fitness domain, aiming to comprehensively cover all aspects of fitness activities, ensuring that the knowledge graph can accurately and effectively describe and associate these key elements. Body parts and anatomical structures serve as the foundation for fitness training, items of exercise and fitness movements represent the core of fitness activities, equipment and tools assist in achieving fitness goals, technical terms help users understand fitness theories, exercise goals are essential for personalized fitness plans, and nutrition plays a crucial role in enhancing training outcomes. These eight entity categories together form the foundation and practical knowledge of the fitness domain. A detailed description of each entity type is provided below:
1.
Body Parts
Body parts include all parts of the body, such as shoulders, limbs, muscles in the lower ribs, and the bottom of the intertubercular groove of the humerus. This also includes specific muscle names and bone names, such as quadriceps, biceps, and humerus.
2.
Items of Exercise
Items of exercise include aerobic, anaerobic, stability training, and training for different body parts, such as basketball, soccer, running, yoga, square dancing, aerobics, abdominal training, leg training, aerobic exercise, competitive sports, and water sports.
3.
Fitness Movement
Fitness movement include exercises for strength training, such as squats, push-ups, bench presses, and pull-ups.
4.
Equipment and Tools
Equipment and tools include those used in exercise types and fitness actions, such as barbells, dumbbells, kettlebells, treadmills, Bulgarian bags, resistance bands, medicine balls, plyometric boxes, swimming pools, and U-shaped slides.
5.
Exercise Goals
Exercise goals include the effects that can be achieved through exercise types and fitness actions, such as weight loss, muscle gain, endurance improvement, and stress relief.
6.
Anatomical Structures
Anatomical structures include terms or fields describing the shape and position of muscles, such as triangular and perioral.
7.
Nutrients
Nutrients include substances related to fitness and nutrition, such as proteins, carbohydrates, vitamins, minerals, and fluids (water, glucose, sodium chloride).
8.
Technical Terms
Technical terms include rules and technical terms in exercise types, such as movement techniques, passing and receiving techniques, dribbling techniques, shooting techniques, ball-handling techniques, and rebounding techniques.
In defining and categorizing relationship types, we considered the various connections and interactions that may exist between entities in the fitness domain. The selection of these relationship types is based on an in-depth analysis of the interactions among entities within the fitness field, aiming to capture the associations between different entities. By defining and categorizing these relationships, we can describe the usage relationships between athletes and sports equipment, the associations between exercise movements and muscle groups, and the connections between fitness goals and required training. A total of 11 relationship types were defined, further refining the structure of the triplet type, namely . The specific explanations of these relationships are as follows:
1.
Location
This relationship describes the specific location of a muscle in the body. For example, the rectus femoris is a bipennate muscle, part of the quadriceps, located in the center of the front of the thigh. It originates from the anterior inferior iliac spine and the upper margin of the acetabulum, wraps around the front of the knee, and attaches to the tibial tuberosity via the patellar ligament. Triplets extracted from the text: , the corresponding type of triplet is: .
2.
Shape
This relationship describes the specific shape of a muscle. For example, the rectus femoris is a bipennate muscle, part of the quadriceps. It originates from the anterior inferior iliac spine and the upper margin of the acetabulum, wraps around the front of the knee, and attaches to the tibial tuberosity via the patellar ligament. This muscle functions to extend the knee and flex the thigh. Triplets extracted from the text: , the corresponding type of triplet is: .
3.
Origin
This relationship describes the origin of a muscle. For example, the rectus femoris is a bipennate muscle, part of the quadriceps, located in the center of the front of the thigh. It originates from the anterior inferior iliac spine and the upper margin of the acetabulum. Triplets extracted from the text: , Triple Type: .
4.
Insertion
This relationship describes the insertion point of a muscle. For example, the rectus femoris is a bipennate muscle, part of the quadriceps, located in the center of the front of the thigh. It attaches to the tibial tuberosity via the patellar ligament. Triplets extracted from the text: , the corresponding type of triplet is: .
5.
Inclusion
This relationship describes one category including another category, reflecting a membership relationship. For example, the quadriceps is a muscle group located on the front of the thigh and includes four heads: the rectus femoris, vastus medialis, vastus lateralis, and vastus intermedius. To strengthen the thigh, it is essential to develop the quadriceps, as it is one of the largest and most powerful muscles in the body. Triplets extracted from the text: , the corresponding type of triplet is: .
6.
Subordination
This relationship is used to describe how one entity belongs to another, reflecting an affiliation or membership relationship. For example, the rectus femoris is a bipennate muscle that is part of the quadriceps. Triplets extracted from the text: , the corresponding type of triplet is: .
7.
Function
This relationship describes the function or effect of a muscle, exercise type, or fitness action. For example, the rectus femoris extends the knee and flexes the thigh. Triplets extracted from the text: , the corresponding type of triplet is: .
8.
Exercise
This relationship describes the target muscle group exercised by a specific exercise or fitness action. For example, the dumbbell curl is an upper arm training exercise that targets the biceps brachii (located on the front of the upper arm) to enhance its strength and shape. Triplets extracted from the text: , the corresponding type of triplet is: .
9.
Usage
This relationship describes the equipment or tools used in a specific exercise or fitness action. For example, the dumbbell curl uses dumbbells to train the biceps brachii. Triplets extracted from the text: , the corresponding type of triplet is: .
10.
Achieve
This relationship describes how one entity helps another entity achieve a specific goal. For example, the dumbbell curl helps in shaping the upper arm by strengthening the biceps brachii. Triplets extracted from the text: , the corresponding type of triplet is: .
11.
Needs
This relationship describes the specific nutritional intake required to support a particular fitness goal. For example, muscle gain requires high protein intake to meet the needs for muscle repair and growth. Triplets extracted from the text: , the corresponding type of triplet is: .
Data annotation
After the detailed definition and classification of entities and relationship types in the fitness domain, we began annotating the processed sample data. To achieve this, we developed a new entity relationship annotation tool—sportskg (http://sportskg.top/#/annotation). Our platform offers comprehensive data annotation capabilities, including entity annotation, relationship annotation, and entity extraction. Users can easily upload TXT files or other data formats via an intuitive web interface and customize annotation content based on their needs. Figure 3 illustrates the entity annotation process on the sportskg platform. In the control panel, buttons for predefined entity and relationship categories are provided. During the annotation process, users first select entities in the text and then click the corresponding category button to annotate them. The selected entities are highlighted in different colors. Once the entity annotation is completed, users can proceed to annotate relationships between entities. By selecting the head and tail entities and clicking the corresponding relationship button, arrows will indicate the direction from the head entity to the tail entity, clearly illustrating their association.
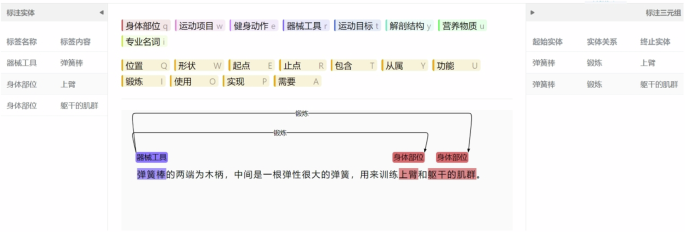
Through this dual annotation mechanism, the platform not only enables accurate annotation of various entity types but also effectively captures and represents the complex relationships between entities. After annotation, the platform not only supports exporting the annotated text but also allows exporting individual triples, greatly facilitating the training of subsequent knowledge extraction models. Additionally, the platform provides functionalities for querying, analyzing, and visualizing the knowledge graph, allowing users to clearly view the relationships between data points. These features enable users to gain deeper insights into the inherent connections within the data, thereby promoting the efficient construction of the knowledge graph.
In the data annotation process using the sportskg platform, manual annotation plays a key role in ensuring the accuracy and completeness of the data. This is because the vocabulary and entity types involved in the annotation process are relatively limited in the early stages, and automated methods are insufficient to meet the requirements. Therefore, manual annotation is central to the entire process. To ensure consistency in the annotation results and eliminate potential subjective differences between annotators, we introduced Cohen’s Kappa(denoted as k)32 coefficient to quantify the inter-annotator agreement. By using this statistical method, we can objectively assess the quality of the annotations, ensuring the efficiency and reliability of the annotation process.The calculation of Cohen’s Kappa is based on the independently annotated results of the annotators. By measuring the difference between observed consistency (P0) and random consistency (Pe), it provides an objective evaluation of the consistency level between the annotators.
The formula is as follows:
$$k=\frac{{P}_{0}-{P}_{e}}{1-{P}_{e}}$$
(1)
$${P}_{0}=\frac{{\sum }_{j=1}^{m}{n}_{{jj}}}{N}$$
(2)
$${P}_{e}=\mathop{\sum }\limits_{j=1}^{m}{p}_{1j}\times {p}_{2j}$$
(3)
P0 represents the proportion of actual observed agreement between the two annotators in the annotation task, while Pe represents the expected proportion of agreement under random conditions. N refers to the total number of annotated samples, and m denotes the total number of categories. njj represents the number of samples for which both annotators agreed on category j. p1j indicates the proportion of samples assigned to category j by Annotator 1, while p2j indicates the proportion of samples assigned to category j by Annotator 2.
The value of Cohen’s Kappa ranges from −1 to 1, where k > 0.8 is generally considered indicative of near-perfect agreement. This method ensures that the quality evaluation of annotation results is based on the independent performance of the annotators, thereby further improving the accuracy and reliability of data annotation.
Entity relationship extraction
Manual annotation ensures the accuracy and high quality of data, however, as the scale of the data grows, the annotation process may face limitations in terms of time and resources. To enhance the scalability of the dataset, we leveraged the high-quality annotated data provided by the sportskg platform to train a span-based joint extraction model, SpERT33. The model aims to automatically learn the patterns between entities and relationships, facilitating the automated extraction of entities and relationships and improving data processing efficiency34,35. SpERT utilizes a feedforward neural network to model spans directly, treating several consecutive tokens within a sentence as a whole. A search approach is employed to capture all possible span forms. The advantage of this method lies in its simplification of the model architecture, enhancement of computational efficiency, and improved ability to handle nested entities by searching for all potential span forms36. Additionally, when performing relation extraction, the SpERT model takes into account the textual features between entities to further improve the accuracy and efficiency of the extraction. The model architecture is shown in Fig. 4.
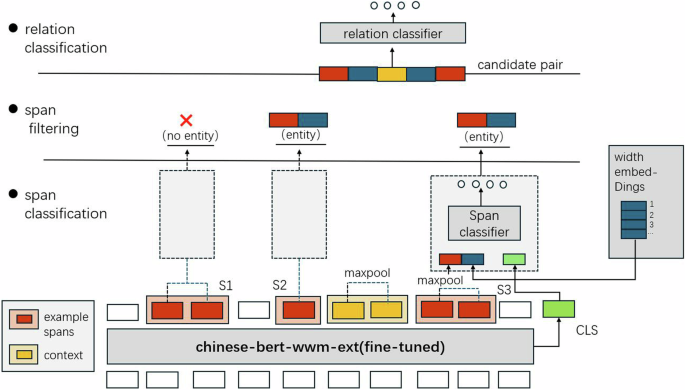
Structure Diagram of the Chinese SpERT33 Model.
We selected chinese-bert-wwm-ext37 as the pre-trained language model and fine-tuned it during the training process. To ensure the robustness of the model, we adopted various parameter settings and optimization strategies, including linear warm-up and decay of the learning rate, dropout techniques, and the initialization of multi-layer classifiers. These strategies help enhance the model’s generalization ability and reduce overfitting.
In terms of data processing, we split the dataset into a training set and a validation set in a 9:1 ratio. The training set was used for model training and parameter optimization, while the validation set was used for evaluating and tuning the model’s performance. Table 1 provides detailed statistical information about the training and validation sets, including the number of sentences and the number of triples. Additionally, Fig. 5 visually presents the distribution of different entity types in these two subsets. The analysis shows that the entity type distributions in the training set and validation set are highly consistent, indicating that the data split is reasonable. Ensuring the reasonableness and representativeness of the coverage of entities and relationships in both the training and validation sets helps provide a comprehensive foundation for model learning and evaluation, thereby improving the overall performance of the model.
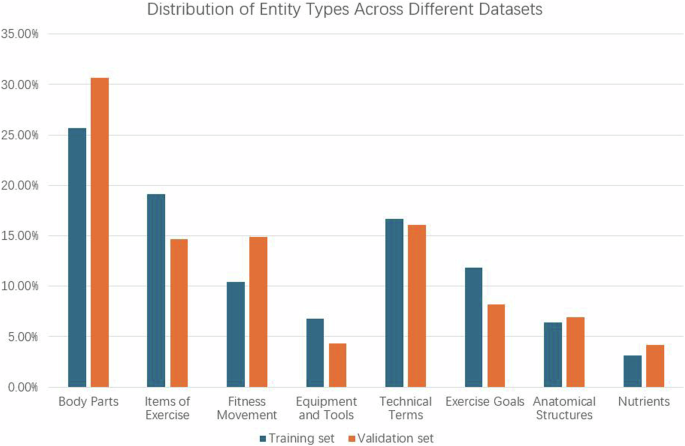
Comparison of Entity Type Distribution in the Training and Validation Sets.
